一、单词边界
目的:** 匹配单个单词**
使用元字符:\b
作用:
1
2
3
4
5
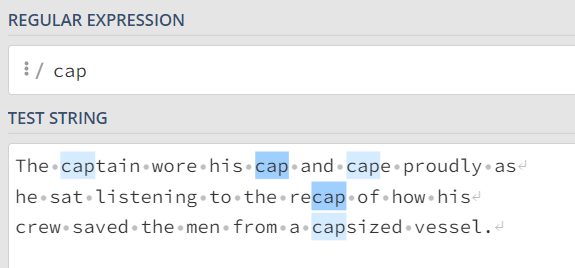
| \b到底匹配什么东西呢?正则表达式引擎不懂英语(事实
上,它不懂任何人类语言),也不知道什么是单词边界。简单地
说,\b匹配的是一个这样的位置,这个位置位于一个能够用来构成单
词的字符(字母、数字和下划线,也就是与\w相匹配的字符)和一个
不能用来构成单词的字符(也就是与\W相匹配的字符)之间。
|
例一
没有使用:\b

使用之后
二、字符串边界
目的:对所要匹配的字符串(在一行的)的开头和(一行的)结尾做出限制
使用元字符:^ 和$
直接上例子
仔细分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
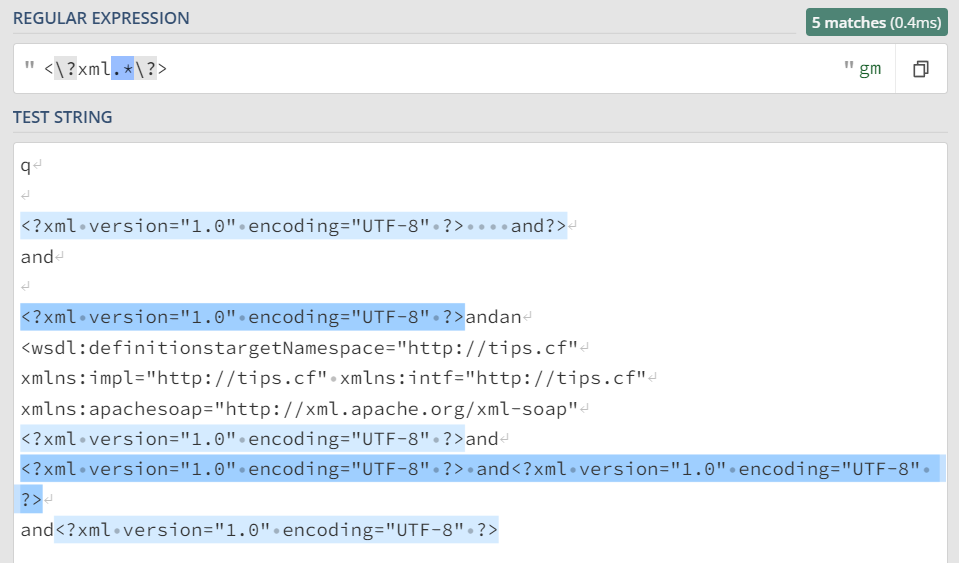
| 首先,"<"匹配第一个字符,随便后的转移之后的"?"匹配第二个字符,xml类似,
重点:
".*"将匹配零个或者多个字符,而这里注意,"."是一个贪婪行字符,
如果其后不加"?"进行修饰为"懒惰型字符",那么会出现意想不到的后果,
上图中
这绝不是我们想要的结果,下图中的第三行"看似没有问题",
如若自己看就会发现,
1.在这一行最后的" and?>"竟然也被匹配了进去!!
2.类似的错误同样出现在倒数第三行。
这就印证了"."这一贪婪型字符它饕餮般的行径(
注意:此处正对应着第五章最后一部分的小知识)
如何解决?加上"?"!
|
但是:
1
2
3
4
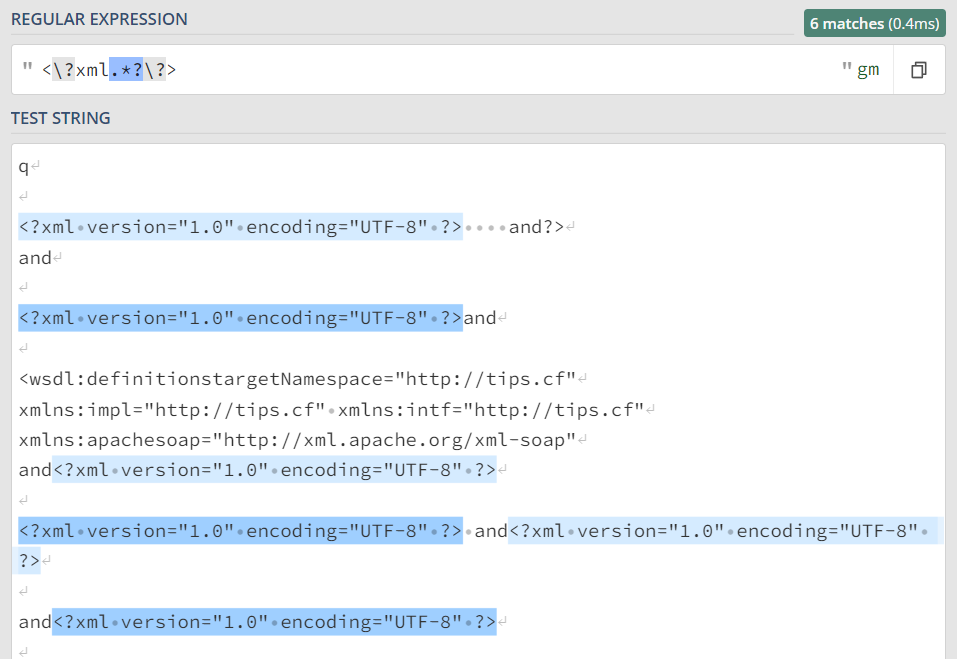
| 问题并没有得到完美解决,尽管我们匹配出了所有的目标,
但是我们还要求所匹配的字段是: 在一行的开头
也就是说第三、五、六个匹配是本不该被匹配的
即:我们要对模式字符串的一行开头做出限制
|
而这正是"^"元字符大显身手的时候
注意:
1
2
3
4
5
6
7
| 还记得吗?我们在第3章里已经见识过元字符^了,但那时的
它是一个用来对字符集合进行“求非”操作的元字符。那它还怎么用来
表明一个字符串的开头呢?
^是几个有着多种用途的元字符之一。只有当它出现在一个字符集合
里(被放在[和]之间)并紧跟在左方括号[的后面时,它才能发挥“求
非”作用。如果是在一个字符集合的外面并位于一个模式的开头,^将
匹配字符串的开头。
|
加上"^"后效果如下图
注意:
这里通常写成
类似的元字符"$"用来修饰字符串的末尾处
目的: 标签的后面不应该再有任何实际内容
例子:
小结
1
2
3
| 正则表达式不仅可以用来匹配任意长度的文本块,还可以用来匹配出现
在字符串中特定位置的文本。\b用来指定一个单词边界(\B刚好相
反)。^和$用来指定字符串边界(字符串的开头和字符串的结束)。
|