有多少个匹配
一 、匹配一个或者多个字符
例一
目的 :匹配文本中的邮箱地址
**使用元字符+ **
用法 :
在字符或者字符集后面简单的加上一个“+“,则可匹配 至少一个符合该字符模式的字符
正则表达式 :[\w.]+@[\w.]+\.\w+

注意:
1
2
3
4
5
| 注意 细心的读者可能已经注意到了:我们没有对字符集合[\w.]里
的.字符进行转义。尽管如此,它还是把原始文本里的.字符匹配出来
了。一般来说,当在字符集合里使用的时候,像.和+这样的元字符将
被解释为普通字符,不需要被转义——但转义了也没有坏处。[\w.]
的使用效果与[\w\ .]是一样的。
|
二 、 匹配零个或者多个字符
例二
目的 :
1
2
3
4
5
| 匹配出合法的邮箱地址(邮箱地址开头不能以`.` 开头,
所以我们的正则表达式需要 可以去匹配出第一个字母或数字,
同时”@“前面也可以只有那**一个**合法字符,而不需要再出现 多个字母数字,
也就是**第一个**合法字符之后的 **字符**是可(**多**)有可**无**的)
|
使用元字符:*
用法与+一致
正则表达式: \w[\w.]*@[\w.]+\.[\w]+
三 : 匹配零个或者一个字符
目的 : 匹配https或者http
使用元字符: ?
?将匹配一个或零个字符或者字符集一次或零次
例三
目的
1
2
3
| 仔细体会?与+和*的相似和区别
之处。如果需要在一段文本里匹配某个特定的字符(或字符集合)而该
字符可能出现、也可能不出现,?无疑是最佳的选择。
|
例四 :匹配指定次数
目的 匹配日期格式
使用元字符 : {}
用法:
1
2
3
4
| {}里面天的数字为所指定的匹配次数
或者
数字区间{x1,x2}(即最少x1次,最多x2次)
|
正则表达式:\d{1,2}[/-]\d{1,2}[-/]\d{0,4}
综合例五
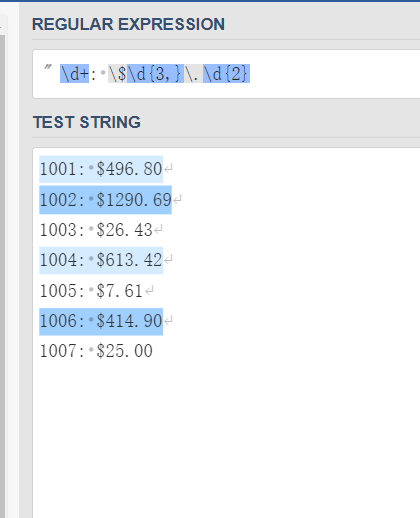
目的: 使用一个正则表达式把所有大于或等于$100美元的金额找出来
使用: {x,}
正则表达式: \d+: \d{3,}\.\d{2}
例六
目的:防止过度匹配
参考表格
| 贪婪型元字符 |
懒惰型元字符 |
| * |
*? |
| + |
+? |
| {n,} |
{n,}? |
贪婪的例子
分析:
1
2
3
4
5
6
7
8
9
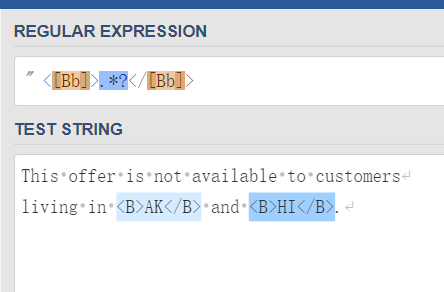
| <[Bb]>匹配<B>标签(大小写均可),</[Bb]>匹配</B>标签(也是大
小写均可)。但这个模式只找到了一个匹配而不是预期中的两个:第一
个<B>标签之后、最后一个</B>标签之前的所有东西——AK</B> and
<B>HI——被.*一网打尽。虽然没有漏掉我们想要匹配的文本,但问题
是第2个<B>标签不明不白地“失踪”了。
为什么会这样?因为*和+都是所谓的“贪婪型”元字符,它们在进行匹配
时的行为模式是多多益善而不是适可而止的。它们会尽可能地从一段文
本的开头一直匹配到这段文本的末尾,而不是从这段文本的开头匹配到
碰到第一个匹配时为止。
|
懒惰版改进(加上”?“)
小结
1
2
3
4
5
6
7
| 正则表达式的真正威力体现在重复次数匹配方面。本章介绍了+(匹配
字符或字符集合的一次或多次重复出现)、*(匹配字符或字符集合的
零次或多次重复出现)、?(匹配字符或字符集合的零次或一次出现)
等几个元字符的用法。要想获得更精确的控制,你可以用{ }语法来精
确地设定一个重复次数或是重复次数的最小值和最大值。元字符分“贪
婪型”和“懒惰型”两种;在需要防止过度匹配的场合下,请使用“懒惰
型”元字符来构造你的正则表达式.
|